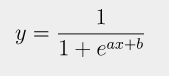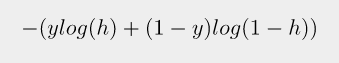Data_set = np.loadtxt("불러올데이터셋경로와파일명.csv", delimiter=",")
# 이 데이터는 속성이 17개고 마지막 열이 클래스이다.
X = Data_set[:,0:17]
Y = Data_set[:,17]
딥러닝 설계하기
# Sequential 함수를 이용해서 딥러닝의 층구조를 만들 것이다.
model = Sequential()
# 은닉층(이자 입력층)을 추가한다.
# Dense 함수를 이용해서 하나의 층의 밀집도를 지정한다.
# 30개의 node와 입력값은 17개, 활성함수는 렐루(relu)를 사용하였다.
model.add(Dense(30, input_dim=17, activation='relu'))
# 출력층을 추가한다.
# 출력층이므로 입력값이 없다. 또한 노드도 당연히 하나다.
# 활성함수는 시그모이드(sigmoid)함수를 사용하였다.
model.add(Dense(1, activation='sigmoid'))
딥러닝 컴파일하기
# 오차 측정 함수는 평균 제곱근 오차를 사용하였고, 최적화는 adam함수를 사용하였다.
# metrics 함수는 모델이 컴파일될 때 모델 수행 결과를 나타나게끔 설정하는 부분이다.
# 정확도를 측정하기 위해 사용되는 테스트 샘플을 학습 과정에서 제외시킴으로써 과적합을 막는다.
model.compile(loss='mean_squared_error', optimizer='adam', metrics=['accuracy'])
딥러닝 구동하기
# 모든 데이터를 30번 돌리고, 한번 돌릴 때 10개의 데이터씩 집어넣으라는 의미이다.
model.fit(X, Y, epochs=30, batch_size=10)
신경망의 핵심 원리는 바로 로지스틱 회기에 있다. 로지스틱 회기는 0과 1을 판별한다고 했다, 퍼셉트론도 가중치(기울기)와 바이어스(y절편)을 이용하여 예측값을 구하고 그러한 예측값들의 합을 가중합이라고 한다. 이러한 가중합들을 활성화함수(시그노이드 등)에 넣어서 최종 예측값을 결정하는 것이다, 이때 예측값은 그것이 맞느냐 아니냐이다.
XOR 문제의 등장으로 인한 해결책은 다층 퍼셉트론
문제는 여기서 나타난 게 xor 문제이다. 가중치, 바이어스, 가중합, 시그노이드만으로 풀 수 없는 문제가 나타난 것이다. 그래서 나타난 것이 다층 퍼셉트론이다. 중간에 은닉층을 두어 공간을 왜곡하는 것이다. 이러한 식으로 은닉층을 여러 개 쌓아올려 복잡한 문제를 해결하는 과정이 뉴런이 복잡한 과정을 거쳐 사고를 하는 사람의 신경망과 닮아있기 때문에 이를 인공 신경망이라고 부르기 시작했다.
오차역전파
지금까지 오차를 계산하고 오차를 줄이는 방식을 공부했었다. 신경망에서 오차를 최적화하는 방식 중 하나는 오차 역전파이다. 구동 방식은 다음과 같다.
1. 임의의 초기의 가중치를 준 뒤 결과를 계산한다.
2. 오차를 구한다.
3. 경사 하강법을 이용해 앞 가중치를 오차가 작아지는 방향으로 업데이트 한다.
4. 1~3의 과정을 더이상 오차가 줄어들지 않을 때까지 반복한다.
기울기 소실 문제
그런데 이때 활성화 함수로 사용된 시그모이드 함수에 문제가 발생했다. 기울기가 0에 수렴하는 현상이 발생한 것이다. 그래서 다른 활성화 함수가 나타났다. 토론토대학교에 제프리 힌튼 교수가 제안한 렐루(ReLU)함수는 시그모이드 함수의 기울기 소실 문제를 해결했다. 그리고 또 뒤이어 나온 것이 소프트플러스(softplus)함수이다.
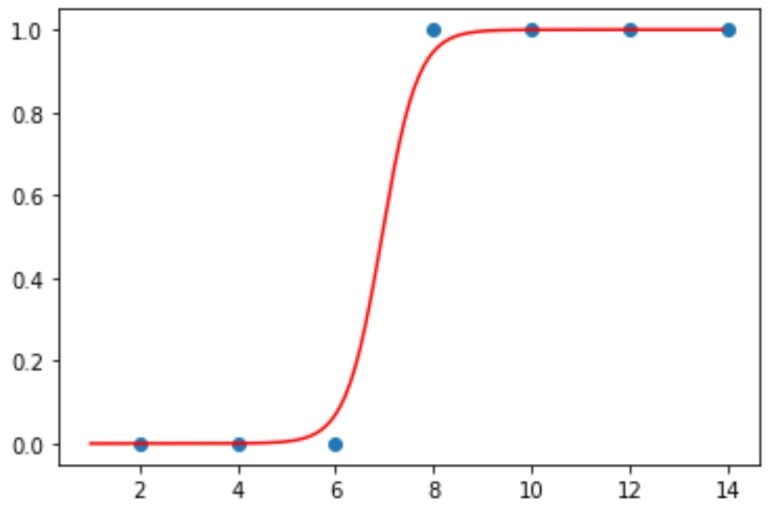
로지스틱 회기란, 참 거짓을 판명하는 ox기계라고 보면 된다. 오로지 1(정답)과 0(오답)뿐이다.
그러한 참 거짓을 나타내는 그래프는 다음과 같고, 이를 시그모이드 함수라고 한다.
시그모이드 함수 (Sigmoid function)
오차공식 = 로그함수
h = 예측값
다중 로지스틱 회기 코드
#-*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
# 실행할 때마다 같은 결과를 출력하기 위한 seed 값 설정
seed = 0
np.random.seed(seed)
tf.set_random_seed(seed)
# x,y의 데이터 값
x_data = np.array([[2, 3],[4, 3],[6, 4],[8, 6],[10, 7],[12, 8],[14, 9]])
y_data = np.array([0, 0, 0, 1, 1, 1,1]).reshape(7, 1)
# 입력 값을 플래이스 홀더에 저장
X = tf.placeholder(tf.float64, shape=[None, 2])
Y = tf.placeholder(tf.float64, shape=[None, 1])
# 기울기 a와 bias b의 값을 임의로 정함.
a = tf.Variable(tf.random_uniform([2,1], dtype=tf.float64)) # [2,1] 의미: 들어오는 값은 2개, 나가는 값은 1개
b = tf.Variable(tf.random_uniform([1], dtype=tf.float64))
# y 시그모이드 함수의 방정식을 세움
y = tf.sigmoid(tf.matmul(X, a) + b)
# 오차를 구하는 함수
loss = -tf.reduce_mean(Y * tf.log(y) + (1 - Y) * tf.log(1 - y))
# 학습률 값
learning_rate=0.1
# 오차를 최소로 하는 값 찾기
gradient_decent = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
predicted = tf.cast(y > 0.5, dtype=tf.float64)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted, Y), dtype=tf.float64))
# 학습
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(3001):
a_, b_, loss_, _ = sess.run([a, b, loss, gradient_decent], feed_dict={X: x_data, Y: y_data})
if (i + 1) % 300 == 0:
print("step=%d, a1=%.4f, a2=%.4f, b=%.4f, loss=%.4f" % (i + 1, a_[0], a_[1], b_, loss_))
# 어떻게 활용하는가
new_x = np.array([7, 6.]).reshape(1, 2) #[7, 6]은 각각 공부 시간과 과외 수업수.
new_y = sess.run(y, feed_dict={X: new_x})
print("공부 시간: %d, 개인 과외 수: %d" % (new_x[:,0], new_x[:,1]))
print("합격 가능성: %6.2f %%" % (new_y*100))
그리고 단순선형회기와 다중선형회기로 나뉘는데 이건 그냥 x가 하나냐 아니면 x가 여러개냐 인 것임
단순선형회기 Simple Linear Regression
먼저, 데이터를 설정해준다.
# 고성능의 수치 계산을 위한 라이브러리 Numpy.
# 데이터 연산시에 자주 사용된다.
import numpy as np
# 데이터 컨셉 설명
# x(학생의 공부 시간), y(공부 시간 x에 따른 점수)
x = [2, 4, 6, 8]
y = [81, 93, 91, 97]
mx = np.mean(x)
my = np.mean(y)
최소 제곱법 (예측 잘~하는 선을 위한 변수 구하기)
기울기 a 구하는 공식
y절편인 b 구하는 공식
위 두 공식을 코드로 표현하기
# 기울기 공식의 분모
divisor = sum([(mx - i)**2 for i in x])
# 기울기 공식의 분자
def top(x, mx, y, my):
d = 0
for i in range(len(x)):
d += (x[i] - mx) * (y[i] - my)
return d
dividend = top(x, mx, y, my)
# 기울기 구하기
a = dividend / divisor
# y절편 구하기
b = my - (mx*a)
평균 제곱근 오차 (RMSE)
최소 제곱법으로 구한 예측값에 대한 오차 구하기
p는 실제값이고 y는 예측값임
# RMSE 함수
def rmse(p, a):
return np.sqrt(((p - a) ** 2).mean())
경사하강법으로 오차수정하기
import tensorflow as tf
data = [[2, 81], [4, 93], [6, 91], [8, 97]]
data_x = [x_row[0] for x_row in data]
data_y = [y_row[1] for y_row in data]
# 기울기 a와 y 절편 b의 값을 임의로 정한다.
# 단, 기울기의 범위는 0 ~ 10 사이이며 y 절편은 0 ~ 100 사이에서 변하게 한다.
a = tf.Variable(tf.random_uniform([1], 0, 10, dtype = tf.float64, seed = 0))
b = tf.Variable(tf.random_uniform([1], 0, 100, dtype = tf.float64, seed = 0))
# y에 대한 일차 방정식 ax+b의 식을 세운다.
y = a * x_data + b
# 텐서플로 RMSE 함수
# y가 예측값이고 y_data가 실제값이다.
rmse = tf.sqrt(tf.reduce_mean(tf.square( y - y_data )))
# 학습률 값 (keras에서는 자동으로 지정해준다.)
learning_rate = 0.1
# RMSE 값을 최소로 하는 값 찾기 (=경사 하강법 사용)
gradient_decent = tf.train.GradientDescentOptimizer(learning_rate).minimize(rmse)
# 텐서플로를 이용한 학습
# Session 함수를 통해 구현될 함수를 텐서플로에서는 '그래프'라고 부른다.
# Session이 할당되면 session.run('그래프명')의 형식으로 해당 함수를 구동시킨다.
with tf.Session() as sess:
# 변수 초기화
sess.run(tf.global_variables_initializer())
# 2001번 실행(0번 째를 포함하므로)
for step in range(2001):
sess.run(gradient_decent)
# 100번마다 결과 출력
if step % 100 == 0:
print("Epoch: %.f, RMSE = %.04f, 기울기 a = %.4f, y 절편 b = %.4f" % (step,sess.run(rmse),sess.run(a),sess.run(b)))
다중 선형 회기 Multiple Linear Regression
import tensorflow as tf
data = [[2, 0, 81], [4, 4, 93], [6, 2, 91], [8, 3, 97]]
x1_data = [x_row1[0] for x_row1 in data]
x2_data = [x_row2[1] for x_row2 in data]
y_data = [y_row[2] for y_row in data]
a1 = tf.Variable(tf.random_uniform([1], 0, 10, dtype=float64, seed=0))
a2 = tf.Variable(tf.random_uniform([1], 0, 10, dtype=float64, seed=0))
b = tf.Variable(tf.random_uniform([1], 0, 100, dtype=float64, seed=0))
y = a1 * x1_data + a2 * x2_data + b
rmse = tf.sqrt(tf.reduce_mean(tf.sqare(y-y_data)))
learning_rate = 0.1
gradient_decent = tf.train.GradientDescentOptimizer(learning_rate).minimize(rmse)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(2001):
sess.run(gradient_decent)
if step % 100 == 0:
print("Epoch: %.f, RMSE = %.04f, 기울기 a1 = %.4f, 기울기 a2 = %.4f, y절편 b = %.4f" % (step,sess.run(rmse),sess.run(a1),sess.run(a2),sess.run(b)))
파이썬이 주언어가 아니라서 코드 문법이 좀 이해가 안돼서 불 편하지만 계속하다보면 머 익숙해지겠지
(★★이 때 중요한 것★★ - 여기서 오류나서 애먹었음) 내 컴퓨터의 파이썬 버전을 python --version으로 확인 후, 알맞게 설정해준다. 아니면 파이썬 버전 설정 자체를 해주지 않는게 낫다. 왜냐면 자동으로 내 버젼으로 연결해주니까.
conda create -n (작업 환경 이름) python=3.9(생략가능)
4. 아나콘다 작업환경을 켜준 후에 tensorflow와 keras를 설치한다.
conda activate (설정한 작업 환경 이름)
pip install tensorflow
pip install keras
케라스랑 텐서플로 둘다 대충 라이브러리인 것 같고, 케라스 라이브러리에는 Sequential 함수랑 Dense 함수가 있고 model 함수를 이용해서 다중 계층을 add로 삽입하여 층 구조를 만들 수 있나봄. 책에서는 딥러닝 프로젝트를 여행으로 비유하자면 텐서플로는 비행기고 케라스는 조종사라는데 아직은 안 와닿음. 일단 넘김ㅅㄱ
5. 파이참에서 아나콘다 연결하는법
유저 > 아나콘다3 > env > python.exe 이 파일이 보여야됨, 없으면 먼가 이상한 거임 (나처럼 애초에 아나콘다 가상 환경 설정시 파이썬 버전 개같이 설정한 건지 확인해야댐) 어쨌든 Interpreter 항목의 주소를 User(님이름) > 아나콘다3 > env > python.exe 로 해야댐
그리고 텐서플로 랜덤 씨드 주는거 메소드 바꼈나봄. 책의 버젼이 더 낮아서 현재 내 버전보다 낮았나봄. 책에 나와있는 메소드로 하면 오류떴었음. 그래서 오류 구글링해서 새로운 메소드 알아냄
# 개같이 오류
tf.set_random_seed(seed)
# 이제 이렇게 작성해야됨
tf.random.set_seed(seed)